Counting sort en Python — el que no compara, cuenta (con animación)
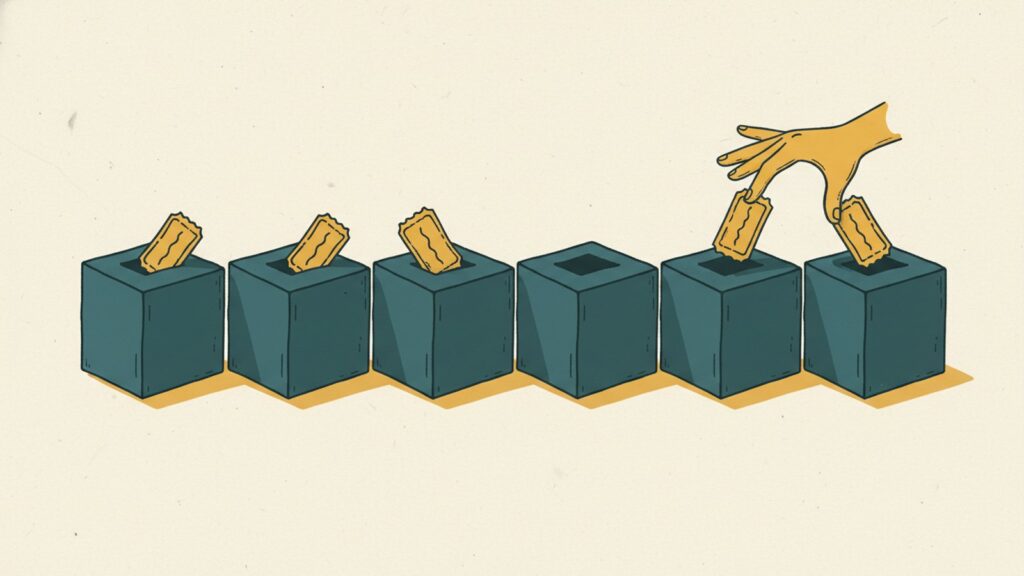
Counting sort es el algoritmo que rompe las reglas del juego. Todos los demás algoritmos del clúster (bubble, quick, merge, heap…) comparan elementos. Por eso están acotados por debajo en Ω(n log n): la información que pueden extraer comparando pares es limitada.
Counting NO compara. Cuenta. Y por eso puede ser lineal, Θ(n + k), donde k es el rango de valores. Es como pasar de “examinar la lista uno por uno” a “delegar el trabajo a la propia memoria”.
La analogía perfecta: imagina un escrutinio electoral. ¿Cómo cuentas votos? No comparas papeleta con papeleta. Las metes en cubos (uno por candidato) y al final cuentas cuántas hay en cada cubo. Eso es counting sort.
Esta entrada cubre el algoritmo en serio: cómo funciona paso a paso, implementación en Python, JavaScript y Java, su complejidad real (incluida la trampa de cuándo NO conviene), y por qué es la base de radix sort.
Si quieres el panorama de los 14 algoritmos del clúster: Algoritmos de ordenación en Python — los 14 explicados.
Contenido
- 1 Counting sort en una frase
- 2 Antes de seguir: qué quieren decir O, Θ y Ω
- 3 Cómo funciona — traza paso a paso
- 4 Implementación en Python
- 5 Implementación en JavaScript
- 6 Implementación en Java
- 7 Complejidad — lineal con asterisco
- 8 Ver en acción — counting sort sobre 10 listas fijas
- 9 Cuándo usar counting sort
- 10 Comparativa rápida
- 11 Mitos que circulan sobre counting sort
- 12 ¿Y en la stdlib de Python?
- 13 Trivia algorítmica
- 14 FAQ rápida
- 15 En resumen
Counting sort en una frase
Crea un array auxiliar de tamaño igual al rango de valores. Cuenta cuántas veces aparece cada valor en la lista original. Reescribe la lista en orden recorriendo los conteos. Total: O(n + k).
Animación sobre 12 valores:
Antes de seguir: qué quieren decir O, Θ y Ω
En las tablas verás los tres símbolos. Idea rápida:
- O(n+k) — “O grande”, cota superior (peor caso).
- Ω(n+k) — “Omega”, cota inferior (mejor caso).
- Θ(n+k) — caso típico.
Counting sort es Θ(n+k) literalmente: mejor y peor caso coinciden. Su comportamiento NO depende del orden de la entrada, solo del rango de los valores. Más detalle en el pilar del clúster.
Cómo funciona — traza paso a paso
Ordenamos [4, 2, 2, 8, 3, 3, 1] (n=7, valores entre 1 y 8).
Fase 1: contar.
Creamos un array cuentas de tamaño 8 (rango 1..8), inicialmente todo a 0. Recorremos la lista incrementando:
índice: 0 1 2 3 4 5 6 7 8
cuentas: _ 0 0 0 0 0 0 0 0
Recorre [4, 2, 2, 8, 3, 3, 1]:
- 4 → cuentas[4]++ → cuentas[4] = 1
- 2 → cuentas[2]++ → cuentas[2] = 1
- 2 → cuentas[2]++ → cuentas[2] = 2
- 8 → cuentas[8]++ → cuentas[8] = 1
- 3 → cuentas[3]++ → cuentas[3] = 1
- 3 → cuentas[3]++ → cuentas[3] = 2
- 1 → cuentas[1]++ → cuentas[1] = 1
Final: cuentas = [_, 1, 2, 2, 1, 0, 0, 0, 1]
Fase 2: reescribir la lista.
Recorremos cuentas en orden ascendente y rellenamos la lista con los valores que toquen:
i=1, cuentas[1]=1 → escribir 1 una vez → lista = [1]
i=2, cuentas[2]=2 → escribir 2 dos veces → lista = [1, 2, 2]
i=3, cuentas[3]=2 → escribir 3 dos veces → lista = [1, 2, 2, 3, 3]
i=4, cuentas[4]=1 → escribir 4 una vez → lista = [1, 2, 2, 3, 3, 4]
i=5, cuentas[5]=0 → no hay nada que escribir
i=6, cuentas[6]=0 → idem
i=7, cuentas[7]=0 → idem
i=8, cuentas[8]=1 → escribir 8 una vez → lista = [1, 2, 2, 3, 3, 4, 8]
Ordenado. Total de operaciones: 7 lecturas (fase 1) + 8 lecturas + 7 escrituras (fase 2) = O(n + k).
📥 Llévate el cheatsheet de Optimización Python (gratis)
PDF de 8 páginas con los patrones que más rendimiento te dan en Python: medir antes de optimizar, complejidad real, estructuras adecuadas, evitar trabajo repetido, profiling y cuándo paralelizar. Para tener al lado cuando algo va lento.
Sin spam. Te apuntas a la lista, descargas el cheatsheet y recibes contenido de rendimiento en Python cada semana.
Implementación en Python
def ordenar(lista: list[int]) -> list[int]:
if not lista:
return lista
minimo, maximo = min(lista), max(lista)
cuentas = [0] * (maximo - minimo + 1)
# Fase 1: contar apariciones.
for v in lista:
cuentas[v - minimo] += 1
# Fase 2: reescribir la lista en orden.
idx = 0
for i, c in enumerate(cuentas):
for _ in range(c):
lista[idx] = i + minimo
idx += 1
return lista
if __name__ == "__main__":
print(ordenar([4, 2, 2, 8, 3, 3, 1])) # [1, 2, 2, 3, 3, 4, 8]
Tres detalles importantes:
minimopara indexar. Si tu lista tiene valores [100, 105, 110, …], no quieres un array de tamaño 110. Usasvalor - minimopara que el primer índice sea 0. Así el array de cuentas es solo del tamaño del rango real.- Doble bucle al reescribir. El interno (
for _ in range(c)) parece anidado, pero el total de iteraciones es exactamente n: cada elemento se escribe una vez. Eso es O(n), no O(n·k). - In-place sobre
lista. No crea una lista nueva, modifica la original. Memoria extra: O(k) paracuentas.
En entrevistas técnicas, el detalle clave: counting sort es estable si lo implementas con prefix sums (ver más abajo). La versión “simple” no lo es realmente — destruye el orden original — pero “preserva” elementos iguales porque los reescribe consecutivos.
Variante con prefix sums (estable y más versátil)
La versión académica usa “prefix sums” sobre las cuentas. Es más compleja pero te da estabilidad real, lo cual importa cuando ordenas objetos por una clave:
def ordenar_estable(lista: list[int]) -> list[int]:
if not lista:
return lista
minimo, maximo = min(lista), max(lista)
cuentas = [0] * (maximo - minimo + 1)
salida = [0] * len(lista)
# Fase 1: contar.
for v in lista:
cuentas[v - minimo] += 1
# Fase 2: prefix sums (cuentas[i] = nº de elementos <= i).
for i in range(1, len(cuentas)):
cuentas[i] += cuentas[i - 1]
# Fase 3: reescribir RECORRIENDO DE DERECHA A IZQUIERDA
# (esto es lo que hace que sea estable).
for v in reversed(lista):
cuentas[v - minimo] -= 1
salida[cuentas[v - minimo]] = v
return salida
Esta variante es la que se usa como subrutina dentro de radix sort.
Implementación en JavaScript
function ordenar(lista) {
if (lista.length === 0) return lista;
const minimo = Math.min(...lista);
const maximo = Math.max(...lista);
const cuentas = new Array(maximo - minimo + 1).fill(0);
for (const v of lista) cuentas[v - minimo]++;
let idx = 0;
for (let i = 0; i < cuentas.length; i++) {
for (let c = 0; c < cuentas[i]; c++) {
lista[idx++] = i + minimo;
}
}
return lista;
}
Implementación en Java
public static void ordenar(int[] lista) {
if (lista.length == 0) return;
int minimo = Arrays.stream(lista).min().getAsInt();
int maximo = Arrays.stream(lista).max().getAsInt();
int[] cuentas = new int[maximo - minimo + 1];
for (int v : lista) cuentas[v - minimo]++;
int idx = 0;
for (int i = 0; i < cuentas.length; i++) {
for (int c = 0; c < cuentas[i]; c++) {
lista[idx++] = i + minimo;
}
}
}
Complejidad — lineal con asterisco
| Métrica | Mejor caso | Caso medio | Peor caso |
|---|---|---|---|
| Tiempo | Ω(n + k) | Θ(n + k) | O(n + k) |
| Memoria | O(n + k) | O(n + k) | O(n + k) |
| Estable | Sí (con prefix sums) | Sí | Sí |
El asterisco crítico: la “k” en n+k es el rango de los valores, no el tamaño de la lista. Si tu lista tiene n=1000 elementos pero los valores van de 1 a 10⁹, k = 10⁹ y necesitas un array auxiliar de mil millones. Inviable.
Cuándo counting sort es brutal:
– n=1.000.000, valores en [0..100] → k=100 → memoria O(n), tiempo O(n).
– n=10.000, valores en [0..30] → k=30 → memoria O(n), tiempo O(n).
Cuándo NO:
– n=10, valores en [0..1.000.000] → k=1M → memoria O(k). Absurdo.
– Valores no enteros (floats, strings, objetos).
Cuando lo aplicas en el escenario correcto, counting bate a cualquier algoritmo comparativo. Cuando lo aplicas mal, te quedas sin memoria. Esa es la lección importante.
Ver en acción — counting sort sobre 10 listas fijas
Todo el clúster usa las mismas 10 listas fijas (n=15):
| # | Nombre | Qué es |
|---|---|---|
| 1 | ordenada | 1, 2, 3, ..., 15 |
| 2 | inversa | 15, 14, ..., 1 |
| 3 | casi_ordenada | 1..15 con un par de swaps |
| 4 | muy_desordenada | Patrón min-max alternado |
| 5 | duplicados | Enteros del rango [1..5] repetidos |
| 6-10 | aleatoria_s1 .. aleatoria_s5 | 5 permutaciones aleatorias deterministas |
Aplicamos counting sort:
from sortlab import bench_estandar, formato_tabla
print(formato_tabla(bench_estandar("counting", n=15)))
Salida real:
Lista Comp. Interc. Escr. Tiempo (ms) Caso Θ observada
--------------- ----- ------- ----- ----------- ---------------------- -----------
ordenada 0 0 15 0.003 Único (no comparativo) Θ(n+k)
inversa 0 0 15 0.003 Único (no comparativo) Θ(n+k)
casi_ordenada 0 0 15 0.003 Único (no comparativo) Θ(n+k)
muy_desordenada 0 0 15 0.003 Único (no comparativo) Θ(n+k)
duplicados 0 0 15 0.002 Único (no comparativo) Θ(n+k)
aleatoria_s1 0 0 15 0.003 Único (no comparativo) Θ(n+k)
aleatoria_s2 0 0 15 0.003 Único (no comparativo) Θ(n+k)
aleatoria_s3 0 0 15 0.003 Único (no comparativo) Θ(n+k)
aleatoria_s4 0 0 15 0.003 Único (no comparativo) Θ(n+k)
aleatoria_s5 0 0 15 0.003 Único (no comparativo) Θ(n+k)
Lectura de la tabla:
Comp. = 0en TODAS las filas. Counting sort literalmente NO compara. No tiene que recorrer pares de elementos: solo “tira al cubo correspondiente”.- `Escr. = 15 (n) siempre. Reescribe la lista entera una vez. Cada elemento se escribe una sola vez durante la fase de reescritura.
- Tiempo uniformísimo: ~3 microsegundos. Da igual la forma de la entrada — counting no se beneficia ni se perjudica de listas ordenadas/inversas/aleatorias.
- La librería lo clasifica como
Único (no comparativo)+ Θ(n+k) — su Θ característica real. Lanes lineal en el tamaño de la entrada y laken el rango de valores (aquí 15 enteros con valores en [1..15], así quek ≈ n, pero en general son magnitudes independientes).
Compara con sus rivales O(n log n) sobre la misma aleatoria_s1:
| Algoritmo | Comparaciones | Tiempo (ms) |
|---|---|---|
| Quicksort | 51 | 0,006 |
| Merge | 40 | 0,010 |
| Heap | 68 | 0,012 |
| Counting | 0 | 0,003 |
Counting es el más rápido en este escenario porque los valores caben en un rango pequeño (1..15). En cuanto el rango crece, la historia cambia: a n=1.000 con valores en [1..1.000.000], counting sería inviable por memoria.
Reproducirlo sin instalar nada
sortlab vive privada en el Python profesional: medir, optimizar y escalar. Versión instrumentada inline:
def counting_medido(lista_original: list[int]) -> dict:
arr = list(lista_original)
escrituras = 0
if not arr:
return {"ordenada": arr, "comparaciones": 0, "escrituras": 0}
minimo, maximo = min(arr), max(arr)
cuentas = [0] * (maximo - minimo + 1)
for v in arr:
cuentas[v - minimo] += 1
idx = 0
for i, c in enumerate(cuentas):
for _ in range(c):
arr[idx] = i + minimo
escrituras += 1
idx += 1
return {"ordenada": arr, "comparaciones": 0, "escrituras": escrituras}
listas = {
"ordenada": list(range(1, 16)),
"inversa": list(range(15, 0, -1)),
"casi_ordenada": [1, 11, 3, 4, 5, 6, 7, 8, 9, 10, 2, 12, 13, 14, 15],
"muy_desordenada": [1, 15, 2, 14, 3, 13, 4, 12, 5, 11, 6, 10, 7, 9, 8],
"duplicados": [1, 1, 3, 2, 2, 2, 1, 5, 1, 5, 4, 1, 1, 1, 2],
}
for nombre, lista in listas.items():
r = counting_medido(lista)
print(f"{nombre:<16} comp={r['comparaciones']:>3} esc={r['escrituras']:>3}")
Verás: comparaciones siempre 0, escrituras siempre 15. La firma de counting.
Cuándo usar counting sort
Sí:
- Listas grandes con valores en un rango pequeño. Edades (0..120), notas (0..100), categorías limitadas, etc. Counting bate a cualquier comparativo.
- Cuando necesitas estabilidad (con prefix sums) y los valores son enteros acotados.
- Como subrutina dentro de radix sort (ver radix).
No:
- Valores reales (float) o tipos no acotados. Counting necesita un índice entero por valor.
- Rango de valores enorme. Si k >> n, la memoria se dispara y deja de tener sentido.
- Como sort de uso general. Para datos “normales” de programación moderna,
sorted()(Timsort) gana en general.
Comparativa rápida
| Algoritmo | Mejor | Peor | Memoria | Estable | Familia |
|---|---|---|---|---|---|
| Quicksort | Ω(n log n) | O(n²) | O(log n) | No | Comparativo |
| Merge | Ω(n log n) | O(n log n) | O(n) | Sí | Comparativo |
| Heap | Ω(n log n) | O(n log n) | O(1) | No | Comparativo |
| Counting | Ω(n+k) | O(n+k) | O(n+k) | Sí | No comparativo |
| Radix | Ω(d·(n+k)) | O(d·(n+k)) | O(n+k) | Sí | No comparativo |
El punto interesante: counting rompe la barrera de Ω(n log n) que tienen los comparativos. Es un resultado matemático real: cualquier algoritmo que ordena comparando pares no puede ir más rápido que n log n en el caso medio. Counting lo evita porque no compara — distribuye.
Mitos que circulan sobre counting sort
- “Counting sort es siempre el más rápido.” Falso. Solo cuando k (el rango) es del orden de n o menor. Si k es enorme, counting es inviable.
- “Counting sort no es estable.” La versión “simple” no destruye el orden de iguales pero tampoco lo preserva por construcción. La versión con prefix sums sí es estable formalmente.
- “Counting sort solo funciona con enteros pequeños.” Funciona con cualquier “valor mapeable a un entero”. Strings de longitud limitada, fechas, IDs categóricos… si puedes definir un mapeo a [0..k], counting funciona.
¿Y en la stdlib de Python?
No, no hay counting sort directo. Lo más cerca: collections.Counter cuenta apariciones de elementos hashables en O(n):
from collections import Counter
c = Counter([4, 2, 2, 8, 3, 3, 1])
print(c) # Counter({2: 2, 3: 2, 4: 1, 8: 1, 1: 1})
Si los valores son enteros con rango pequeño, te puedes hacer un counting sort en 3 líneas:
from collections import Counter
def counting_basico(lista):
c = Counter(lista)
return [v for v in sorted(c) for _ in range(c[v])]
Pero ojo: este “atajo” usa sorted() por dentro, que es Timsort. Si querías counting sort puro como técnica algorítmica, implémentalo tú.
Trivia algorítmica
Counting sort lo describió Harold H. Seward en su tesis de máster de 1954 en el MIT. Su trabajo describía algoritmos para ordenación en máquinas de cinta magnética — donde el coste de comparaciones era mucho más alto que en RAM, así que evitar comparaciones era oro. Es uno de los algoritmos clásicos que sigue vivo no porque sea elegante, sino porque resuelve un nicho real.
FAQ rápida
¿Counting sort funciona con números negativos?
Sí, con el truco del minimo: usas valor - minimo como índice del array de cuentas. Hace que el rango efectivo sea siempre [0..k].
¿Es realmente lineal?
Sí, en su escenario (k del orden de n). El “O(n+k)” significa exactamente eso.
¿Es estable?
La versión con prefix sums sí. La versión simple “preserva” elementos iguales por construcción pero no lo es formalmente.
¿Sirve para ordenar strings?
Sí, si los strings tienen longitud acotada y los caracteres están en un alfabeto finito (típicamente ASCII o Unicode BMP). Es la base de algoritmos como Burst Sort.
¿Te ha valido esto?
Si te ha resultado útil, llévate el cheatsheet de Optimización Python en PDF — 8 páginas con cómo medir, cuándo importa la complejidad, qué estructura usar y profiling práctico. Para tener al lado cuando algo va lento. Gratis.
Sin spam. Email + cheatsheet de rendimiento + un correo por semana sobre medir y optimizar Python.
En resumen
Counting sort es el algoritmo que rompe el límite de Ω(n log n) de los comparativos porque no compara: cuenta. Es brutal cuando los valores están en un rango pequeño (edades, notas, categorías…) y la única razón por la que no es el rey de la ordenación es que necesita un array auxiliar de tamaño k. Si conoces tus datos, counting es a menudo la respuesta correcta.
Si quieres aprender a detectar cuándo un algoritmo no comparativo va a ganar —no solo a recitar Big-O sin contexto— ese es el camino del curso de El Pythonista.
¿Quieres aprender Python en orden, no a saltos?
Esto que has leído es solo una pieza. En El Pythonista lo verás todo encadenado: 11 módulos, 37+ horas de vídeo, 734 actividades y un proyecto real (MovieTracker) que crece contigo desde la primera variable hasta el deploy a producción.
37+ horas · 734 actividades · Proyecto real · Acceso de por vida · 14 días de garantía


