Radix sort en Python — ordenar dígito a dígito (con animación)
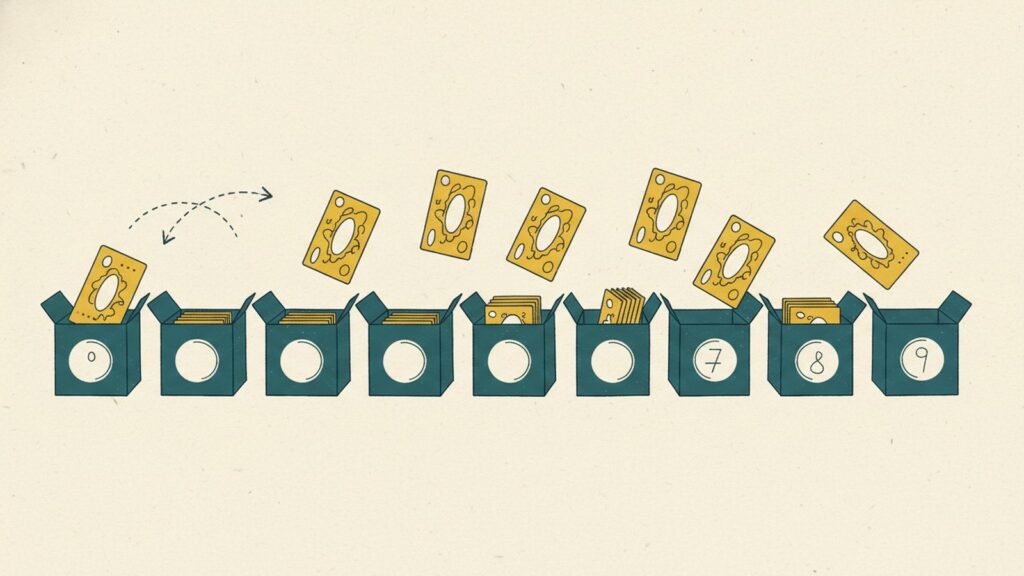
Radix sort es la extensión natural de counting sort cuando el rango de valores es demasiado grande para counting puro. La idea: en vez de ordenar por el valor entero, ordena dígito a dígito, empezando por el menos significativo. Cada pasada por dígito usa counting sort como subrutina. Resultado: O(d·(n+k)), donde d = nº de dígitos y k = base del sistema numérico (típicamente 10).
La analogía perfecta: imagina ordenar un archivo de fichas por DNI. ¿Cómo lo harías?
- Pones las fichas en 10 cajas según la última cifra del DNI.
- Las recoges en orden (caja 0, caja 1, …, caja 9), manteniendo el orden dentro de cada caja.
- Vuelves a meterlas en cajas, ahora por la penúltima cifra.
- Repites por la antepenúltima, anteantepenúltima, …
Cuando has procesado todas las cifras, las fichas están ordenadas por DNI. Sin comparar DNIs entre sí ni una sola vez.
Esta entrada cubre el algoritmo en serio: cómo funciona paso a paso, implementación en Python, JavaScript y Java, su complejidad real (incluida la trampa), y cuándo bate a quicksort.
Si quieres el panorama de los 14 algoritmos del clúster: Algoritmos de ordenación en Python — los 14 explicados.
Contenido
- 1 Radix sort en una frase
- 2 Antes de seguir: qué quieren decir O, Θ y Ω
- 3 Cómo funciona — traza paso a paso
- 4 Implementación en Python
- 5 Implementación en JavaScript
- 6 Implementación en Java
- 7 Complejidad — lineal en n, con asterisco en d
- 8 Ver en acción — radix sort sobre 10 listas fijas
- 9 Cuándo usar radix sort
- 10 Comparativa rápida
- 11 Mitos que circulan sobre radix sort
- 12 ¿Y en la stdlib de Python?
- 13 Trivia algorítmica
- 14 FAQ rápida
- 15 En resumen
Radix sort en una frase
Ordena la lista por el dígito menos significativo (unidades). Luego por el siguiente (decenas). Y así. Cada pasada es estable (preserva orden anterior). Cuando terminas todos los dígitos, la lista está ordenada.
Animación sobre 12 valores:
Antes de seguir: qué quieren decir O, Θ y Ω
En las tablas verás los tres símbolos. Idea rápida:
- O(d·(n+k)) — “O grande”, cota superior (peor caso).
- Ω(d·(n+k)) — “Omega”, cota inferior (mejor caso). Tiene que hacer las d pasadas pase lo que pase.
- Θ(d·(n+k)) — caso típico.
Radix sort es Θ(d·(n+k)) literalmente: las tres coinciden. Da igual el orden de la entrada — siempre hace d pasadas sobre n elementos. Más detalle en el pilar del clúster.
Cómo funciona — traza paso a paso
Ordenamos [170, 45, 75, 90, 802, 24, 2, 66] (n=8, base 10, valores con hasta 3 cifras).
Pasada 1: ordena por la cifra de las UNIDADES.
Agrupamos en cubos según la última cifra de cada número:
unidades: 0 1 2 3 4 5 6 7 8 9
cubo: [170, [], [802, [], [24, [45, [66, [], [], [],
90] 2] ], 75, ],
, ]
Wait, déjame organizarlo mejor:
Valor 170 → última cifra 0 → cubo 0
Valor 45 → última cifra 5 → cubo 5
Valor 75 → última cifra 5 → cubo 5
Valor 90 → última cifra 0 → cubo 0
Valor 802 → última cifra 2 → cubo 2
Valor 24 → última cifra 4 → cubo 4
Valor 2 → última cifra 2 → cubo 2
Valor 66 → última cifra 6 → cubo 6
Recogiendo en orden (cubo 0, 1, 2, ..., 9):
[170, 90, 802, 2, 24, 45, 75, 66]
Pasada 2: ordena por la cifra de las DECENAS.
Valor 170 → decenas 7 → cubo 7
Valor 90 → decenas 9 → cubo 9
Valor 802 → decenas 0 → cubo 0
Valor 2 → decenas 0 → cubo 0
Valor 24 → decenas 2 → cubo 2
Valor 45 → decenas 4 → cubo 4
Valor 75 → decenas 7 → cubo 7
Valor 66 → decenas 6 → cubo 6
Recogiendo:
[802, 2, 24, 45, 66, 170, 75, 90]
Pasada 3: ordena por la cifra de las CENTENAS.
Valor 802 → centenas 8 → cubo 8
Valor 2 → centenas 0 → cubo 0
Valor 24 → centenas 0 → cubo 0
Valor 45 → centenas 0 → cubo 0
Valor 66 → centenas 0 → cubo 0
Valor 170 → centenas 1 → cubo 1
Valor 75 → centenas 0 → cubo 0
Valor 90 → centenas 0 → cubo 0
Recogiendo:
[2, 24, 45, 66, 75, 90, 170, 802]
Ordenado. Tres pasadas para 8 elementos con hasta 3 cifras → 3 × 8 = 24 operaciones de distribución. Comparado con quicksort sobre el mismo input (~20-30 comparaciones), radix está en el mismo orden — pero sin comparar dos valores ni una vez.
La clave: cada pasada es estable. Si dos valores tienen la misma cifra en la posición actual, mantienen su orden previo. Por eso al terminar la última pasada (la cifra más significativa), los valores están ordenados de menor a mayor.
📥 Llévate el cheatsheet de Optimización Python (gratis)
PDF de 8 páginas con los patrones que más rendimiento te dan en Python: medir antes de optimizar, complejidad real, estructuras adecuadas, evitar trabajo repetido, profiling y cuándo paralelizar. Para tener al lado cuando algo va lento.
Sin spam. Te apuntas a la lista, descargas el cheatsheet y recibes contenido de rendimiento en Python cada semana.
Implementación en Python
def ordenar(lista: list[int]) -> list[int]:
if not lista:
return lista
maximo = max(lista)
exp = 1 # 1, 10, 100, ... (la posición que estamos ordenando)
while maximo // exp > 0:
_ordenar_por_digito(lista, exp)
exp *= 10
return lista
def _ordenar_por_digito(lista: list[int], exp: int) -> None:
"""Counting sort estable usando solo el dígito en la posición `exp`."""
salida = [0] * len(lista)
cuentas = [0] * 10 # base 10
# Fase 1: contar apariciones del dígito.
for v in lista:
cuentas[(v // exp) % 10] += 1
# Fase 2: prefix sums (para estabilidad).
for i in range(1, 10):
cuentas[i] += cuentas[i - 1]
# Fase 3: reescribir DE DERECHA A IZQUIERDA (preserva estabilidad).
for i in range(len(lista) - 1, -1, -1):
d = (lista[i] // exp) % 10
cuentas[d] -= 1
salida[cuentas[d]] = lista[i]
lista[:] = salida
if __name__ == "__main__":
print(ordenar([170, 45, 75, 90, 802, 24, 2, 66]))
# [2, 24, 45, 66, 75, 90, 170, 802]
Detalles importantes:
- Solo funciona con enteros no negativos. Para negativos, hay que tratarlos aparte (separar negativos de positivos, ordenar cada grupo, recomponer).
- Base 10 es la elección clásica, pero podrías usar base 2 (binario) o 256 (un byte) según convenga. Las bases más grandes hacen menos pasadas pero usan más memoria por cubo. Base 256 es óptima para ordenar enteros de 32 bits → 4 pasadas en lugar de 10.
- El truco de la estabilidad: la fase 3 recorre la lista de derecha a izquierda y decrementa el counter antes de usarlo. Eso garantiza que los elementos iguales mantengan su orden original — clave para que la ordenación por dígitos sucesivos funcione.
En entrevistas, el detalle clave: radix sort necesita que el counting sort interno sea estable. Si pierdes la estabilidad, una pasada destruiría el orden de la anterior y el algoritmo no funcionaría.
Implementación en JavaScript
function ordenar(lista) {
if (lista.length === 0) return lista;
const maximo = Math.max(...lista);
let exp = 1;
while (Math.floor(maximo / exp) > 0) {
ordenarPorDigito(lista, exp);
exp *= 10;
}
return lista;
}
function ordenarPorDigito(lista, exp) {
const salida = new Array(lista.length);
const cuentas = new Array(10).fill(0);
for (const v of lista) cuentas[Math.floor(v / exp) % 10]++;
for (let i = 1; i < 10; i++) cuentas[i] += cuentas[i - 1];
for (let i = lista.length - 1; i >= 0; i--) {
const d = Math.floor(lista[i] / exp) % 10;
cuentas[d]--;
salida[cuentas[d]] = lista[i];
}
for (let i = 0; i < lista.length; i++) lista[i] = salida[i];
}
Implementación en Java
public static void ordenar(int[] lista) {
if (lista.length == 0) return;
int maximo = Arrays.stream(lista).max().getAsInt();
for (int exp = 1; maximo / exp > 0; exp *= 10) {
ordenarPorDigito(lista, exp);
}
}
private static void ordenarPorDigito(int[] lista, int exp) {
int[] salida = new int[lista.length];
int[] cuentas = new int[10];
for (int v : lista) cuentas[(v / exp) % 10]++;
for (int i = 1; i < 10; i++) cuentas[i] += cuentas[i - 1];
for (int i = lista.length - 1; i >= 0; i--) {
int d = (lista[i] / exp) % 10;
cuentas[d]--;
salida[cuentas[d]] = lista[i];
}
System.arraycopy(salida, 0, lista, 0, lista.length);
}
Complejidad — lineal en n, con asterisco en d
| Métrica | Mejor caso | Caso medio | Peor caso |
|---|---|---|---|
| Tiempo | Ω(d·(n+k)) | Θ(d·(n+k)) | O(d·(n+k)) |
| Memoria | O(n+k) | O(n+k) | O(n+k) |
| Estable | Sí | Sí | Sí |
Las variables:
– n = número de elementos.
– d = número de dígitos del valor máximo (en la base elegida).
– k = base del sistema (típicamente 10 → cubos del 0 al 9).
El asterisco de la complejidad: parece lineal porque d y k son “pequeñas constantes”. Pero atención: si tus valores son enteros de 64 bits, d ≈ 20 (en base 10) o d ≈ 8 (en base 256). Para n=1.000, eso son 20.000 operaciones vs ~10.000 que haría quicksort. Radix puede perder si los valores son enormes.
Regla práctica: radix gana cuando d ≪ log₂(n). Si tus enteros caben en 32 bits y n es grande, sí. Si son enteros enormes y n es modesto, no.
Por qué SÍ es estable: porque cada pasada interna (counting sort por dígito) preserva el orden de iguales. La estabilidad es esencial: la pasada por unidades ordena por unidades, manteniendo lo que ya estaba ordenado por… bueno, nada todavía. La pasada por decenas mantiene la ordenación por unidades dentro de cada decena. Y así.
Ver en acción — radix sort sobre 10 listas fijas
Todo el clúster usa las mismas 10 listas fijas (n=15):
| # | Nombre | Qué es |
|---|---|---|
| 1 | ordenada | 1, 2, 3, ..., 15 |
| 2 | inversa | 15, 14, ..., 1 |
| 3 | casi_ordenada | 1..15 con un par de swaps |
| 4 | muy_desordenada | Patrón min-max alternado |
| 5 | duplicados | Enteros del rango [1..5] repetidos |
| 6-10 | aleatoria_s1 .. aleatoria_s5 | 5 permutaciones aleatorias deterministas |
Aplicamos radix sort:
from sortlab import bench_estandar, formato_tabla
print(formato_tabla(bench_estandar("radix", n=15)))
Salida real:
Lista Comp. Interc. Escr. Tiempo (ms) Caso Θ observada
--------------- ----- ------- ----- ----------- ---------------------- -----------
ordenada 0 0 30 0.006 Único (no comparativo) Θ(n+k)
inversa 0 0 30 0.006 Único (no comparativo) Θ(n+k)
casi_ordenada 0 0 30 0.006 Único (no comparativo) Θ(n+k)
muy_desordenada 0 0 30 0.006 Único (no comparativo) Θ(n+k)
duplicados 0 0 15 0.003 Único (no comparativo) Θ(n+k)
aleatoria_s1 0 0 30 0.006 Único (no comparativo) Θ(n+k)
aleatoria_s2 0 0 30 0.006 Único (no comparativo) Θ(n+k)
aleatoria_s3 0 0 30 0.006 Único (no comparativo) Θ(n+k)
aleatoria_s4 0 0 30 0.006 Único (no comparativo) Θ(n+k)
aleatoria_s5 0 0 30 0.006 Único (no comparativo) Θ(n+k)
Lectura de la tabla:
Comp. = 0en TODAS las filas. Radix sort, como counting, no compara nunca. Es un algoritmo no comparativo puro.Escr. = 30(= 2n) en casi todas. Para n=15 y valores [1..15], necesita 2 pasadas (unidades y decenas, porque 10..15 tienen 2 cifras). Cada pasada escribe los 15 elementos → 30 escrituras totales.duplicados→ 15 escrituras (= n). Como los valores son [1..5] (todos de un solo dígito), radix solo necesita 1 pasada. La belleza de “se adapta al rango real de los valores”.- El clasificador devuelve Θ(n+k) en todas las filas — radix sort es no comparativo y su complejidad real es Θ(d·(n+k)) con
d= número de dígitos yk= base del sistema (10 aquí). Para n=15 con valores ≤ 15, d=2 y k=10: trabajo total ≈ 2·(15+10) ≈ 50 operaciones. La columnaCasoesÚnico (no comparativo)porque la complejidad no depende de cómo esté ordenada la entrada — solo del rango de valores.
Compara con counting sort sobre la misma lista (cifras reales):
| Algoritmo | Escrituras (typical) | Cuándo es mejor |
|---|---|---|
| Counting | 15 (= n, una pasada) | Valores con rango k pequeño y conocido |
| Radix | 30 (= d·n, d=2 para n=15) | Valores con rango k grande, pero pocos dígitos |
Counting es lineal puro (Θ(n)) cuando puedes pagar k de memoria. Radix paga “log n veces más operaciones” pero necesita menos memoria (solo k para los cubos, no n+k).
Reproducirlo sin instalar nada
sortlab vive privada en el Python profesional: medir, optimizar y escalar. Versión instrumentada inline:
def radix_medido(lista_original: list[int]) -> dict:
arr = list(lista_original)
escrituras = 0
if not arr:
return {"ordenada": arr, "comparaciones": 0, "escrituras": 0}
maximo = max(arr)
exp = 1
while maximo // exp > 0:
salida = [0] * len(arr)
cuentas = [0] * 10
for v in arr:
cuentas[(v // exp) % 10] += 1
for i in range(1, 10):
cuentas[i] += cuentas[i - 1]
for i in range(len(arr) - 1, -1, -1):
d = (arr[i] // exp) % 10
cuentas[d] -= 1
salida[cuentas[d]] = arr[i]
for i in range(len(arr)):
arr[i] = salida[i]
escrituras += 1
exp *= 10
return {"ordenada": arr, "comparaciones": 0, "escrituras": escrituras}
listas = {
"ordenada": list(range(1, 16)),
"inversa": list(range(15, 0, -1)),
"duplicados": [1, 1, 3, 2, 2, 2, 1, 5, 1, 5, 4, 1, 1, 1, 2],
"aleatoria_s1": [15, 11, 1, 14, 7, 6, 4, 9, 8, 12, 5, 2, 13, 10, 3],
}
for nombre, lista in listas.items():
r = radix_medido(lista)
print(f"{nombre:<16} esc={r['escrituras']:>3}")
Verás: comparaciones siempre 0; escrituras = n para valores de 1 dígito, 2n para valores de 2 dígitos.
Cuándo usar radix sort
Sí:
- Enteros de bits limitados (32 o 64 bits) donde quieres bajar de O(n log n) a O(n).
- Cuando ordenas IDs, fechas YYYYMMDD, DNIs, números de teléfono — cualquier cosa que se mapee a entero corto.
- Cuando counting puro no cabe en memoria porque k es enorme. Radix divide el problema en d pasadas con cubos pequeños.
No:
- Floats, strings de longitud variable, objetos genéricos. Radix necesita “el dígito i” del valor, así que requiere una estructura digital uniforme. Para strings se puede adaptar (MSD radix sort) pero es más complejo.
- n pequeño. El overhead de las d pasadas no compensa frente a quick/merge.
Comparativa rápida
| Algoritmo | Tiempo | Memoria | Estable | Familia |
|---|---|---|---|---|
| Quicksort | Θ(n log n) | O(log n) | No | Comparativo |
| Merge | Θ(n log n) | O(n) | Sí | Comparativo |
| Counting | Θ(n+k) | O(n+k) | Sí | No comparativo |
| Radix | Θ(d·(n+k)) | O(n+k) | Sí | No comparativo |
| Timsort | Θ(n log n) | O(n) | Sí | Comparativo |
El paralelismo bonito: counting es lineal cuando k es manejable. Radix lo extiende a casos donde k es enorme dividiendo en d pasadas. Es la herramienta que usas cuando counting no cabe en memoria.
Mitos que circulan sobre radix sort
- “Radix sort es siempre lineal.” Es Θ(d·n). Si d es pequeño (4-8 para enteros típicos), parece lineal. Si d es enorme (números arbitrariamente grandes), no lo es tanto.
- “Solo funciona con enteros positivos.” Funciona con cualquier cosa mapeable a enteros: fechas, IDs, strings de longitud fija… Los negativos se tratan aparte (separar, ordenar, recomponer).
- “Radix es más rápido que quicksort siempre.” No. Para n pequeños o valores de muchos dígitos, quicksort gana. Radix brilla cuando n es grande y d es pequeño.
¿Y en la stdlib de Python?
No directamente. Python usa Timsort. Si necesitas radix, te lo implementas (~30 líneas).
Curiosidad: NumPy tiene radix sort interno en algunas operaciones de ordenación de arrays de enteros pequeños — porque es claramente más rápido que Timsort en ese escenario específico. np.sort(arr, kind='radixsort') lo expone (en versiones recientes).
Trivia algorítmica
Radix sort tiene un antecedente físico: las máquinas tabuladoras de Herman Hollerith (las que se usaron para el censo de EEUU de 1890) ordenaban tarjetas perforadas por radix sort. Cada columna de la tarjeta era un dígito; la máquina las distribuía físicamente en cajas por columna. Lo que hoy hacemos en software se hizo durante décadas con cartón y metal. Hollerith fundó la empresa que después se convirtió en IBM.
FAQ rápida
¿Por qué empezar por el dígito menos significativo (LSD) y no por el más significativo (MSD)?
LSD (Least Significant Digit) es más fácil de implementar y siempre estable. MSD (Most Significant Digit) puede ser más rápido en algunos casos pero es más complejo (requiere recursión por subgrupos). La versión clásica es LSD.
¿Funciona con strings?
Sí, si tienen longitud fija. Para longitud variable, hay variantes (MSD radix sort) más complicadas.
¿Es estable?
Sí, intrínsecamente. Es esencial: si pierdes la estabilidad en una pasada, las siguientes destruyen el orden previo.
¿Cuál es la base óptima?
Empíricamente, base 256 (un byte) suele ser óptima para enteros de 32-64 bits: pocas pasadas (4-8), cubos manejables (256). Base 10 es la “didáctica”.
¿Radix supera a quicksort en la práctica?
Para n grande y enteros de bits limitados, sí. Para n pequeño o valores enormes, no. Depende del escenario.
¿Te ha valido esto?
Si te ha resultado útil, llévate el cheatsheet de Optimización Python en PDF — 8 páginas con cómo medir, cuándo importa la complejidad, qué estructura usar y profiling práctico. Para tener al lado cuando algo va lento. Gratis.
Sin spam. Email + cheatsheet de rendimiento + un correo por semana sobre medir y optimizar Python.
En resumen
Radix sort es la extensión natural de counting sort: cuando los valores tienen rango demasiado grande para counting puro, divides el problema en d pasadas (una por dígito) y obtienes O(d·n). No compara nunca, pero a cambio necesita que tus valores se mapeen a algo “digital” (enteros, strings de longitud fija…). Es la pieza que NumPy y bases de datos usan internamente cuando ordenan grandes arrays de enteros.
Si quieres aprender a detectar cuándo un algoritmo no comparativo va a hacer milagros con tus datos —y a reconocer que sorted() no siempre es la respuesta— ese es el camino del curso de El Pythonista.
¿Quieres aprender Python en orden, no a saltos?
Esto que has leído es solo una pieza. En El Pythonista lo verás todo encadenado: 11 módulos, 37+ horas de vídeo, 734 actividades y un proyecto real (MovieTracker) que crece contigo desde la primera variable hasta el deploy a producción.
37+ horas · 734 actividades · Proyecto real · Acceso de por vida · 14 días de garantía


